目录
文章转载于:个性化沙盒会是每个人的第三只手 - 王焱的文章 - 知乎 作者:王焱
链接:https://zhuanlan.zhihu.com/p/1978863528287966982
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
零、背景
沙盒现在是 agent 必不可缺的一部分,沙盒加大模型可以理论上模拟人类所有的操作。 并且随着沙盒技术的不断迭代,还会创造出新的玩法。
现在每个人已经把个人云盘视作理所当然的事情。但二十年前,云盘刚出现的时候,很多人会质疑,我有移动硬盘了,这个的需求真的那么大么?
同理,未来每个人也会有一个自己独属的沙盒,你在这个沙盒上的所有操作都会持久化的保存起来。 未来每个人都会有一个私人沙盒,像你的第三只手一样。
这里对比 docker 和 microVM,分析两种技术的差异。 通过对比,告诉大家为什么 microVM 更好,会更适配这种技术方案。
除了本地沙盒这个特例外,常见沙盒技术方案有两种,docker 和 microVM(firecracker)。 docker 来自于当年大家开发完软件后,想要实现一次打包,满世界部署的需求。 microVM 来自于 AWS 的内部虚拟机需求。既要硬件级隔离(安全),又要容器级敏捷(百毫秒、几 MB),产物就是这个“极薄”的 VMM——Firecracker。 microVM 出发点跟 Agent 的沙盒需求更接近,理论上更适配 Agent 的沙盒需求。 事实上也是如此,我们内部做实验和探索的时候,经过分析,初阶需求,docker 可以的,microVM 一定可以。但高阶需求,microVM 可以的,docker 往往就比较难了。 本篇文章会做一个详细的展开和探讨,为什么 microVM 的上限更高。
接下来四篇的 Agent 文章。 基于 dify 和 n8n 的对比,什么才是一个好的 workflow 框架? 基于 openhands/openmanus/suna 等的对比,什么才是一个好的自主决策 agent 框架? Agent 时代的产品经理需要新增什么技能?像做自媒体一样做 Agent。 Agent 智能硬件开发的流程和坑点。 写完有一段时间了,也会改改放出来。
这篇文章是团队成员——不喝可乐 完成的,经过了多轮的思考和讨论。
一、为什么需要隔离?
1.1 隔离的本质是什么?
这并不是技术,而是迫切的需求,在计算机系统中,隔离要解决三个核心问题:安全、资源、环境
不同时代的隔离技术,侧重点不同:
- 操作系统进程隔离:主要解决安全 和资源
- 容器技术(Docker):主要解决环境
- 虚拟机技术(Firecracker):三者都要,且要求更高的安全
1.1.1 从操作系统角度:进程隔离的起源
核心问题 :在多任务操作系统中,如果不隔离进程会发生什么呢?
历史教训:MS-DOS 时代的混乱 在 1981-1995 年的 MS-DOS 时代,操作系统没有进程隔离 。这导致了三大灾难:
a. 内存冲突:任何程序都能访问任意内存地址 比如,游戏程序的 bug 可能覆盖文档编辑器的数据,就会导致文件损坏,数据丢失 b. 系统崩溃:一个程序的错误会导致整个系统死机 c. 安全漏洞:病毒可以直接读写任何程序的内容,严重会导致密码,隐私信息的丢失
技术突破:虚拟内存的诞生 为了解决这些问题,现代操作系统引入了虚拟内存 机制
核心原理: a. 每个进程看到的是虚拟地址 ,而不是真实的物理地址 b. CPU 的 MMU(内存管理单元)自动转换地址 c. 操作系统维护页表 ,控制访问权限
实际效果: 进程 A:虚拟地址 0x1000 → 物理地址 0x5000 进程 B:虚拟地址 0x1000 → 物理地址 0x8000 两个进程都以为自己在用 0x1000,但实际在不同位置!
进程隔离的局限性:无法隔离环境 虽然虚拟内存解决了内存安全问题,但所有进程仍然共享同一个操作系统环境 。这导致了新的问题: 局限性 1:依赖冲突,机器上比如有 2 个 Python 项目,用到两个版本的 Py,问题是系统只能安装一个版本,指向一个版本,这就会导致启动时库的冲突。 局限性 2:环境不一致,代码可能在开发环境正常运行,但是部署出去,可能会出现各种 Bug,比如遇到系统库不兼容,依赖版本不匹配
所以其实本质上,进程隔离(虚拟内存)仅仅是解决了内存安全,进程独立,但其他功能依然是共享的,并没有解决环境问题,这就是为什么需要容器技术(Docker)
1.2 不同时代的隔离需求变化
隔离技术的演进,从本质上来讲,是需求驱动的,不同时代的计算场景,对隔离的需求完全不一样
1.2.1 云计算机时代:Docker 与容器隔离
时代背景:云计算和微服务的兴起 基于进程隔离的局限性,这里就导入了 Docker 的核心理念了,打包整个环境 Docker 的官方定义:一个用于开发、发布和运行应用程序的开发平台。Docker 可以让你把应用和基础设施分开,因此可以进行快速交付。
什么是容器? 容器是针对应用每个组件的隔离进程。每个组件都运行在独立的环境中,完全与机器上的其他东西进行隔离;无论什么应用,均可打包成统一的镜像,可以在开发,测试,生产环境无缝运行
容器的优势呢? 每个容器包含运行所需的一切:代码、运行时、系统工具、库,不依赖主机上的预装依赖;容器隔离运行,对主机和其他容器影响最小,有一定的安全性;每个容器独立管理,拥有自己的生命周期,删除并不会影响其他容器;容器可以在任何地方运行,开发机器上的容器在数据中心或云端以相同方式工作。
Docker 的技术实现 底层技术:Linux Namespace + Cgroups Docker 通过 Linux 内核的两大特性实现隔离: Namespace :隔离进程、网络、文件系统、主机名等(7 种隔离) Cgroups :限制 CPU、内存、磁盘 I/O 等资源使用 就是为什么 Docker 能实现"环境隔离",但仍然"共享内核"。
Docker 的局限性呢? 核心问题:所有容器均共享宿主主机内核 这就会有一个比较严重的问题,若内核有漏洞,所有容器均会受影响,恶意容器可能通过内核漏洞逃逸到宿主机,那么在多租户的场景下,就会大大展现安全性的不足。 小结:Docker 完美的解决了 "环境" 问题,但是在"安全"方面还不够。特别是在 Serverless、AI Agent 等需要运行不可信代码的场景。这就是为什么 E2B 这个沙盒没有用 Docker 作为底层,而是使用 Firecracker。
1.2.2 Serverless/Agent 时代:Firecracker 与硬件级隔离
时代背景:不可信代码的挑战 全新的应用场景
- Serverless :AWS 需要运行成千上万用户的函数
- AI Agent:ChatGPT 等 AI 需要执行生成的代码
- 代码沙盒:在线 IDE 等代码系统需要运行不可信代码
核心特点:需要运行用户提交的任意代码;这个需求中,就需要完全保证多租户隔离,恶意代码维护,硬件级别隔离来防护
那么,Docker 为什么就显得不够用了呢? 回顾 1.2.1 的结论:
- Docker 共享内核:所有容器共享宿主主机内核;
- 容器逃逸风险:CVE 等漏洞证明了不够安全
- 多租户困难:AWS 不能让任一一个恶意用户攻击其他任何用户
AWS 的真实困境:AWS Lambda 需要在同一台物理机器上运行数千上万个不同客户的函数,若使用 Docker,这其实是做不到的,安全性必须放在首要地位,这是不可被替代的,同时,在商业上,也是完全不可被接受的,所以需要虚拟机级别的隔离 ,但同时又需要保持容器级别的速度。
Firecracker 的核心理念:安全 + 速度 Firecracker 是一个开源的虚拟化技术,专为创建和管理安全、多租户的容器和函数服务而设计的 技术实现: 核心技术:KVM + 极简化
-
硬件虚拟化:基于 KVM (kernel Virtual Machine) 创建 micro VM
- 利用 CPU 的虚拟化指令(Intel VT-x / AMD-V)
- 每个 microVM 有独立的 Guest 内核
- 硬件级隔离
-
最小化攻击面:移除不必要的设备和功能,减少安全风险
- 只支持 4 种设备:网络、块设备、串口、vsock
- 移除:USB、PCI、声卡、显卡、BIOS 等
-
资源隔离:独立的 vCPU、内存、网络、存储
- 每个 microVM 有独立的资源配额
- 防止资源抢占
-
系统调用过滤:使用 seccomp 限制可用的系统调用
- 阻止危险的系统调用
- 减少攻击面
-
Jailer 进程:通过 cgroup、namespace、chroot 进一步隔离
- cgroup:资源限制
- namespace:进程隔离
- chroot:文件系统隔离
核心对比:
| 指标 | 数值 | 对比 Docker |
|---|---|---|
| 启动时间 | ≤ 50ms | Docker: 几秒 |
| 创建速率 | 5 microVMs/核/秒 | 36 核可达 180 VMs/秒 |
| 内存开销 | < 5MB(VMM 进程) | Docker: 几 MB |
| 隔离级别 | 硬件级(独立内核) | Docker: 进程级(共享内核) |
总结: E2B 为什么选择 Firecracker? 关于这点,我们需要知道 E2B 的设计核心理念,在后续章节会有详细介绍
二、Docker 为什么在 Agent 时代不够用?
2.1 Docker 容器沙盒的应用场景
2.1.1 Daytona 的定位:AI 代码执行沙盒
- 运行 AI 代码,用于 AI 生成代码的安全且弹性的基础设施 核心特征:
| 特性 | 指标 | 说明 |
|---|---|---|
| 启动速度 | < 90ms | 从代码到执行的沙盒创建时间 |
| 隔离性 | 分离且隔离的运行时 | 零风险执行 AI 生成的代码 |
| 持久化 | 无限持久化 | 沙盒可以永久存活 |
| 兼容性 | OCI/Docker 兼容 | 可使用任何 Docker 镜像 |
| 并行化 | 大规模并行 | 支持并发 AI 工作流 |
为什么选择 Docker? 从 Daytona 的代码和定位可以看到,Docker 是 AI Agent 时代代码沙盒的首选方案,其实理由很简单:
- 生态成熟:海量的预构建镜像,完善的工具链,后台社区支持强大
- 易于使用:用户可以使用 Dockerfile 定义环境,简单的 API
- 性能优秀:接近原生态,启动快
- 成本低:可提供高密度部署,资源利用率高
2.1.2 典型应用场景
场景 1:AI Agent 代码执行
- 典型产品:ChatGPT code、Daytona 等等
- 需求:AI 生成的代码需要在安全环境中执行
- 隔离 AI 生成的代码(可能有 bug),提供完整的运行环境,快速创建/销毁,成本可控
场景 2:CI/CD 流水线
- 典型产品:GitHub Actions、GitLab CI 等等
- 需求:自动化构建和测试,隔离不同的构建任务,并行执行多个任务,可复现的构建环境
- 环境隔离:不同任务互不干扰,每次构建可使用相同镜像,可以同时运行多个容器
2.1.3 Docker 沙盒的优势总结
Docker 容器是 AI Agent 时代代码沙盒的首选方案,但这有且仅限于:
- 信任的用户(团队内部)
- 单租户使用
- 对成本敏感的场景
- 需要快速迭代的场景
但对于多租户,不可信代码的场景,Docker 的安全性就暴露无疑 接下来,我们以 Daytona 为例子,深入分析 Daytona 沙盒的实现细节
2.2 Daytona : 基于 Docker 的代码沙盒
2.2.1 Daytona 的架构设计
核心架构(三层理解)
2.2.1.1 API Service:业务逻辑层
核心职责:
- 沙盒编排 :处理用户的创建/启动/停止/销毁请求,管理沙盒完整生命周期
- Runner 调度 :根据区域(Region)、类别(Class)、快照(Snapshot)选择合适的 Runner
- 资源管理 :验证组织的 CPU/内存/磁盘配额,防止资源超限
- 权限控制 :基于 API Key 验证用户身份和权限
- 状态持久化 :通过数据库持久化沙盒状态,处理异步状态变更(如构建中、启动中)
- 核心服务:
- SandboxService :沙盒 CRUD、自动停止/归档/删除的定时任务
- RunnerService :Runner 健康检查、容量管理、分配决策
- SnapshotService :镜像构建请求、状态跟踪
- WarmPoolService :预热池管理,实现 Sub-90ms 启动
2.2.1.2 Runner:编排层(Docker 容器的实际管理者)
核心职责:
- 容器管理 :直接调用 Docker API 创建、启动、停止、删除容器
- 镜像操作 :构建镜像(docker build)、拉取镜像(docker pull)、缓存检查
- Daemon 注入 :在容器创建时将静态二进制文件(daemon-amd64)注入容器内
- 状态缓存 :维护沙盒状态的内存缓存(减少对 API Service 的查询)
- 指标暴露 :提供 HTTP API 给 API Service 查询资源使用情况
2.2.1.3 SDK/CLI:用户接口层(Python/TypeScript)
核心职责:
- 简化 API 调用 :将 HTTP REST API 封装为简洁的方法(如 daytona.create())
- 状态轮询 :自动等待异步操作完成(如镜像构建、沙盒启动)
- 错误处理 :统一的异常类型和错误信息
- 开发者体验 :提供类型提示、自动补全、文档
2.2.2 数据流:从请求到执行
text1. 用户调用SDK daytona.create(language="python") ↓ 2. SDK发送HTTP请求到API Service POST /api/v1/sandbox ↓ 3. API Service验证权限和配额 - 检查API Key - 验证CPU/内存配额 ↓ 4. API Service选择合适的Runner - 根据Region、Class、Snapshot选择 - 优先选择有镜像缓存的Runner ↓ 5. API Service转发请求给Runner POST /runner/sandbox/create ↓ 6. Runner调用Docker API - 拉取镜像(如果本地没有) - 创建容器配置 - 创建并启动容器 - 注入Daemon ↓ 7. Runner返回容器ID给API Service ↓ 8. API Service更新数据库状态 状态:创建中 → 运行中 ↓ 9. SDK轮询状态,等待完成 ↓ 10. 返回沙盒对象给用户
2.2.3 关键设计:Warm Pool 机制
问题: Docker 容器启动虽然快(几秒),但是对于用户来说,其实还是不够看的,还是慢!! 解决方案:预热容器池(Warm Pool) 工作原理:系统启动时,与创建 N 个容器
textdocker run -d --name warm-1 python:3.11 sleep infinity
用户请求到来,从池中取出一个容器,注入用户配置和代码,立即可用 用户结束后,清理容器,创建新的预热容器补充池 效果:启动时间:可能从原来的 5s 降到了 90 ms,这里用户就可以体验到一个无感的启动效率了 这就不得不提起 WarmPoolService 的职责了,它是维护预热容器池,监控池的大小(最大/最小容器),根据使用情况动态调整池大小,定期清理长时间未使用的容器 但,这又需要提出来一个致命问题,Warm Pool 只解决了速度上的问题,并没有解决安全上的问题,接下来,我们继续看 Daytona 是如何加固 Docker 容器的安全性的
2.3 Docker 沙盒的安全加固
2.3.1 Daytona 的安全策略:资源隔离优先
从代码角度出发:
texthostConfig := &container.HostConfig{ Privileged: true, // ⚠️ 特权模式 Resources: container.Resources{ CPUPeriod: 100000, CPUQuota: sandboxDto.CpuQuota * 100000, // CPU限制 Memory: sandboxDto.MemoryQuota * 1024 * 1024 * 1024, // 内存限制 MemorySwap: sandboxDto.MemoryQuota * 1024 * 1024 * 1024, // Swap限制 }, StorageOpt: map[string]string{ "size": fmt.Sprintf("%dG", sandboxDto.StorageQuota), // 磁盘限制 },
我们可以看到,这里有严格的 CPU、内存、磁盘限制,并且是 Privileged,接下来,我们从这些角度出发
2.3.2 资源限制:防止 DOS 攻击
textCPUPeriod: 100000, // 100ms周期 CPUQuota: sandboxDto.CpuQuota * 100000, // 配额
若 CpuPeriod = 1 ,容器最多使用 1 vCPU,这就是防止单个容器独占整个 CPU
textMemory: sandboxDto.MemoryQuota * 1024 * 1024 * 1024, MemorySwap: sandboxDto.MemoryQuota * 1024 * 1024 * 1024,
若 MemoryQuota = 2,容器最多使用 2GB 内存,禁用 Swap,防止性能下降,超过限制时,容器会被 kill
textif filesystem == "xfs" { hostConfig.StorageOpt = map[string]string{ "size": fmt.Sprintf("%dG", sandboxDto.StorageQuota), } }
限制容器的磁盘使用量,防止恶意代码填满磁盘,只在 XFS 文件系统上生效
2.3.3 特权模式的风险与权衡
首先,什么是特权模式?
- 容器内可以访问宿主机所有设备(/dev)
- 可以加载内核模块
- 可以修改系统参数
- 几乎用于宿主机 root 等量的权限
为什么 Daytona 使用特权模式?这其实是会有安全风险的
- 支持 Docker in Docker 能力,因为 AI Agent 可能需要在沙盒里面在启 Docker,给到 Agent 最大的权限,拥有最大的能力
- 支持系统级别操作,由于可能会需要调试系统级别问题
- 减少兼容性问题,提高效率
但这样其实无疑会带来比较高级别的安全风险
- 容器逃逸:攻击者可以利用特权来访问宿主机
- 内核攻击:可以加载恶意内核模块
- 设备访问:可以访问宿主机的所有设备
2.3.4 Docker 沙盒的安全加固方案
所以若想加固 Daytona 的安全性,
- 我们得关闭特权模式,这样可以大大降低容器逃逸风险,同理,会牺牲在沙盒里面使用 Docker 的能力
- 启用 Seccomp,相当于一个白名单,限制容器可以调用的系统调用能力
- 启用 User Namespace,自定义映射,容器内的 root 映射到宿主机的普通用户,即使逃逸,也只是拥有普通用户的权限
等等 但这些加固又会带来问题,复杂度加深,兼容性下降,功能受限等等
2.4 Docker 在 Agent 时代的局限性
2.4.1 回顾:Docker 解决了什么问题
Docker 的贡献:
- 环境一致性:Dockerfile 定义环境,任意地方运行
- 依赖隔离::每个容器独立的文件系统
- 快速部署:秒级启动(Warm Pool 可达 < 90ms)
- 资源效率:高密度部署,成本低
- 生态成熟:海量镜像,工具链完善
由此可见,Docker 其实在云计算时代,可以算是非常完美的解决方案了 但是 Docker 在安全 和 功能性 上形成了两难的境界了
2.4.2 Agent 时代的新挑战
新的安全需求
- 不可信代码:AI 生成的代码可能有 bug / 恶意行为
- 多租户隔离:成千上万用户的代码在同一台机器上运行
- 零信任:比较假设每个用户都是潜在的恶意用户,这很重要
- 硬件级隔离:软件层的防御是不够看的
这就是为什么需要更强的隔离,这就是为什么需要 Firecracker!!!
三、Firecracker 的设计权衡
3.1 回顾 Docker 为什么不够用?
3.1.1 Docker 的根本问题:共享内核
架构:假设有 3 个容器在一台机器上运行,其实均是使用一个宿主机内核,在一个内核空间,内核漏洞影响所有容器,若容器逃逸,则会获取宿主机权限 Daytona 的矛盾:
- 使用 Docker 容器作为沙盒
- 但开启 Privileged: true(特权模式)
- 承诺"安全隔离",但实际上共享内核
- 这本身就是一个对立的局面
3.1.2 Firecracker 解决方案:独立内核
| Docker 的问题 | Firecracker 的解决方案 |
|---|---|
| 共享内核 | 每个 microVM 独立内核 |
| 内核漏洞影响所有容器 | 内核漏洞只影响单个 VM |
| 容器逃逸 = 宿主机权限 | VM 逃逸仍在 KVM 隔离内 |
| 特权模式风险高 | 不需要特权模式 |
| 多租户不安全 | 硬件级隔离,天然支持多租户 |
3.2 什么是 Firecracker?
Firecracker 是一个新型虚拟化技术,通过 microVM(微型虚拟机)提供接近容器的速度 和接近传统虚拟机的安全隔离 。
核心特征:
- 灵活的资源配置
- 支持 1-32 个 vCPU
- 任意内存大小组合
- 动态调整资源
- HTTP API 控制
- 每个 microVM 通过进程内 HTTP 服务器暴露 API
- RESTful 接口管理 VM 生命周期
- 通过 Unix Socket 通信
- 极致性能(官方数据) 冷启动(从零启动全新 VM):
- 启动时间:≤ 125ms
- 内存开销:< 5MB(VMM 进程)
- CPU 性能:> 95%裸金属性能
- 创建速率:5 microVMs/核心/秒
热启动(使用快照恢复):
- 使用 UFFD 快照:20-50ms
- 不使用 UFFD 快照:30-80ms
- 跳过最耗时的 Guest Kernel 启动
- 按需加载内存页(mmap + Copy-on-Write)
- 极简设计
- 只保留必要的虚拟设备
- 移除不必要的功能
- 减少攻击面
Firecracker 是一个极简的虚拟机监控器(VMM),专为高密度、多租户的 Serverless 场景优化,提供了接近容器的启动速度 和接近传统虚拟机的安全隔离 。
3.3 Firecracker 的核心技术和性能原理
3.3.1 极简设计:为什么 VMM 只有 5MB?
" 如果这不是我们设计所必须要的,我们不会去构建它" 传统 VMM (QEMU) vs Firecracker
| 组件 | 传统 VMM(QEMU) | Firecracker | 影响 |
|---|---|---|---|
| VMM 大小 | 50-100MB | < 5MB | 启动更快 |
| BIOS | SeaBIOS | 无 | 跳过 BIOS 初始化 |
| PCI 总线 | 完整模拟 | 无 | 减少设备初始化 |
| USB/显卡/声卡 | 支持 | 无 | 减少攻击面 |
| 网络 | 多种模式 | VirtIO Net | 只保留必要的 |
| 存储 | 多种模式 | VirtIO Block | 只保留必要的 |
Firecracker 这种保留设计,会大大减少初始化时间,从可能的几秒降到了几十毫秒,并且有效的减少了攻击面
3.3.2 冷启动:如何做到 ≤ 125 ms?
启动时间分解:
textVMM 启动 (CPU 时间) 加载 firecracker 二进制,初始化 API Server KVM 初始化 创建 VM,配置 vCPU 和内存 Guest Kernel 加载 从磁盘上读取vmlinux.bin,设置启动参数 Guest Kernel 启动 (最耗时) 解压内核,初始化内存,加载驱动,挂载rootfs
这里的 Guest Kernel 启动是最耗时的,基本占领冷启动总耗时的一半了,但是快照功能,完美的规避了这一耗时任务
3.3.3 热启动 - 快照技术
核心思想:跳过最耗时的 Guest Kernel 启动 快照组成:
textFirecracker 快照 memfile(Guest 内存文件) 完整的虚拟机内存状态 vmstate(MicroVM 状态文件) vCPU 寄存器 设备状态(virtIO Block、VirtIO Net) KVM 状态 rootfs.ext4(磁盘文件)
快照恢复流程: 传统冷启动:(≤ 125ms): VMM 启动 → KVM 初始化 → 加载 Kernel → Guest Kernel 启动 → 应用启动 快照恢复(20-50ms): VMM 启动 → 读取快照元数据 → mmap 映射内存 → 恢复 VM 状态 → 启动 vCPU → 应用恢复 跳过了:Guest Kernel 启动(~70ms)
这里的关键技术: 关键技术:
- mmap() MAP_PRIVATE :内存映射,不实际加载
- Copy-on-Write :写时复制,节省内存
- 按需加载 :Guest 访问时才加载内存页
性能数据:
- 不使用 UFFD:30-80ms
- 使用 UFFD:20-50ms
3.3.4 UFFD - 为什么不能在快呢?
问题:传统 mmap 的瓶颈 Guest 访问内存 → 缺页异常 → 陷入内核 → 加载内存页 → 返回用户空间 每次缺页都需要陷入内核,开销大 UFFD 的解决方案:用户态缺页处理
- Firecracker 创建 userfaultfd
- 注册内存区域(ioctl UFFDIO_REGISTER)
- 启动 UFFD 处理线程(监听缺页事件)
- VM 启动(内存为空)
- Guest 访问内存 → 触发缺页
- KVM 捕获 → 通知 UFFD(不陷入内核)
- UFFD 线程决定加载策略: 智能批量加载(预测下一步需要的页),从本地/网络/解压加载 减少缺页次数
- Guest 继续执行
3.3.5 多层安全隔离
这里在 1.2.2 小节完美诠释,这里不再赘述
3.3.6 高密度部署
官方数据提供:36 核机器,每秒可创建 180 个 microVM,这就代表每核心每 200ms 可以创建一个 VM 这里的数据其实是很夸张的,但是认真分析,其实并非无道理,为什么可以做到呢?
- 轻量级 VMM (≤ 5 MB),每个 VM 只需要 5 MB 内存
- 快速启动,冷热启其实都很快
- 并行创建,多个 VM 可以同时并行启动,不需要等待前一个 VM 完全启动
- 资源超卖 vCPU 超卖:36 核可以创建 100+ vCPU,原理:不是所有 VM 都同时满负载,适合 Serverless 场景(短时突发)
3.3.7 小结 Firecracker 的性能秘诀
三大核心技术:
- 极简设计
- 快照 + UFFD
- 资源超卖 + 高密度
3.4 决策分析
选择 Docker 场景: 团队内部开发环境,信任的用户,对成本要求敏感,需要简单调用 选择 Firecracker 的场景: 多租户平台,运行不可信代码(AI Agent),高安全需求,Serverless 场景 Firecracker 是非常强大的,但是也同样,超级底层,Firecracker 仅仅只是一个 VMM,没有上层封装,需要手动管理网络、存储、快照;需要自己实现 API、编排、监控。 所以 E2B 跟随着时代的需求 出现了 在 Firecracker 之上构建完整的沙盒平台,提供了 Template 系统(从 Dockerfile 到快照),提供 SDK、API、编排、监控,让我们可以像使用 Docker 那样简单的使用 Firecracker。
四、E2B:基于 Firecracker 的生产级沙盒平台
4.1 E2B 的整体架构
4.1.1 四层架构设计
textSDK层(Python/TypeScript/Go) REST API API Service层(HTTP/gRPC) gRPC Orchestrator层(Firecracker编排) Unix Socket API Firecracker + envd层(microVM运行时)
各层职责:
| 层级 | 组件 | 职责 | 技术栈 |
|---|---|---|---|
| SDK 层 | Python/TS SDK | 提供开发者友好的 API | Python/TypeScript |
| API 层 | API Service | 请求路由、认证、限流 | Go + HTTP/gRPC |
| 编排层 | Orchestrator | 管理 Firecracker 进程、网络、快照 | Go + KVM |
| 运行时层 | Firecracker + envd | microVM 执行、文件系统、进程管理 | Rust + Go |
4.1.2 核心组件关系
Orchestrator 的核心职责:
- 管理 Firecracker 进程生命周期
- 配置网络(TAP 设备、iptables)
- 管理快照(创建、上传、下载)
- Template 构建(Dockerfile → 快照)
- 资源调度和监控
envd 的核心职责:
- 运行在 microVM 内部的守护进程
- 提供文件系统操作 API
- 提供进程管理 API
- 处理代码执行请求
- 端口转发
4.2 Template 系统 :从 Dockerfile 到 Firecracker 快照
4.2.1 Template 的设计理念
问题:为什么需要 Template?
- Firecracker 只能加载 Linux Kernel 和 rootfs
- 用户需要自定义环境(Python、Node.js、依赖包)
- 每次从零构建太慢
E2B 的解决方案:Template 系统
- 用户用 Dockerfile 定义环境
- E2B 构建成 Docker 镜像
- 转换成 Firecracker 快照
- 快照可以 20-50ms 启动
4.2.2 E2B 的混合架构
Docker + Firecracker 混合架构 这是 E2B 独特的设计:构建用 Docker ,运行用 Firecracker 建阶段(使用 Docker): 用户 Dockerfile → Docker 构建 → Docker 镜像 → 导出文件系统 运行阶段(使用 Firecracker): rootfs.ext4 → Firecracker 快照 → 20-50ms 启动 microVM 为什么这样设计呢?
| 阶段 | 技术选择 | 原因 |
|---|---|---|
| 构建 | Docker | 生态成熟,用户熟悉 Dockerfile,构建工具链完善 |
| 运行 | Firecracker | 硬件级隔离,安全性高,启动快(20-50ms) |
优势:给予我们的体验,我们只需要写 Dockerfile,不需要继续学习 Firecracker,运行沙盒,我们拥有的就是 Firecracker 硬件级的隔离,构建时利用 Docker 缓存,运行时,快照启动 20 - 50 ms 相比于 Dayton
| 项目 | 构建 | 运行 | 安全性 |
|---|---|---|---|
| Daytona | Docker | Docker | 低(共享内核) |
| E2B | Docker | Firecracker | 高(硬件隔离) |
4.2.3 Template 构建流程
完整流程(基于代码)
textStep 1: 用户定义Template配置 ,e2b.Dockerfile(环境定义),e2b.toml(配置:vCPU、内存、磁盘、启动命令) start_cmd(可选的启动脚本); 配置示例(e2b.toml): vcpu_count = 2 memory_mb = 1024 disk_size_mb = 1024 start_cmd = "npm start" Step 2: 构建Docker镜像 , 基础镜像:e2bdev/base:latest ,执行Dockerfile指令 ;安装依赖(apt-get、pip、npm); 复制代码 配置环境变量 生成Docker镜像 Step 3: Docker镜像 → rootfs.ext4 ,启动临时Docker容器 , 导出容器文件系统(docker export),创建ext4文件系统(mkfs.ext4),挂载ext4文件系统 ,复制Docker导出的文件到ext4,注入envd二进制文件 ; 配置systemd启动envd 卸载并保存rootfs.ext4 Step 4: 创建Firecracker快照 ,分配网络槽位(TAP设备、IP地址), 启动NBD设备(挂载rootfs.ext4) , 启动Firecracker进程 ; 配置vCPU、内存; 加载Linux Kernel(vmlinux-6.1.102);挂载rootfs(通过VirtIO Block); 启动Guest Kernel, 等待envd就绪 ,执行start_cmd(环境初始化;例如:npm install、pip install ,暂停microVM(Pause API), 创建快照 ; memfile(Guest内存文件); vmstate(VM状态文件) 上传快照到对象存储(S3/GCS) Step 5: 用户使用Template , SDK调用:sandbox = Sandbox(template="python") , Orchestrator下载快照(如果本地没有缓存); 20-50ms恢复microVM 用户代码开始执行
4.2.4 Template 的关键技术
Docker ---> rootfs 转换
| 步骤 | 技术 | 说明 |
|---|---|---|
| 导出文件系统 | docker export | 导出容器的完整文件系统 |
| 创建 ext4 | mkfs.ext4 | 创建 ext4 文件系统 |
| 注入 envd | 复制二进制 | 将 envd 复制到/usr/local/bin/ |
| 配置启动 | systemd | 配置 envd 开机自启 |
快照优化技术:
- UFFD 按需加载
- 快照恢复时不实际加载全部内存
- Guest 访问时才加载内存页
- 启动时间:20-50ms
2.快照共享
- 多个 Sandbox 可以共享只读快照
- 使用 Copy-on-Write
- 节省内存和存储
3.增量快照(未来优化)
- 只保存变化部分
- 减少存储空间
- 加快上传/下载速度
Template 缓存机制: 本地缓存:下载的快照文件缓存在本地,LRU 策略淘汰不常用的快照,加速 Sandbox 创建 对象存储:S3/GCS 存储所有 Template 快照,按 BuildID 组织,支持版本管理
4.3 核心架构
4.3.1 架构总览与分层
- 四层架构模型
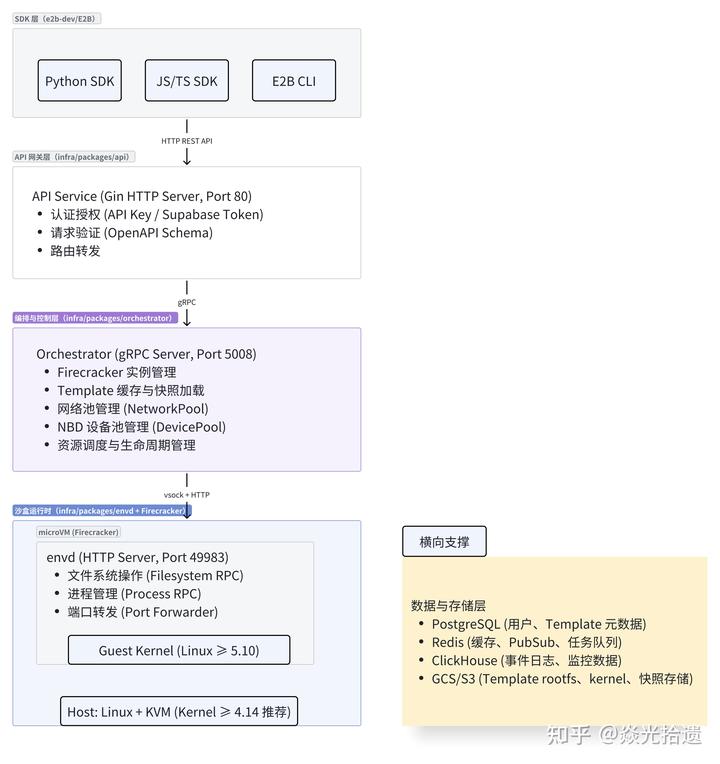
2.两个代码库职责划分
- e2b-dev/infra:服务端基础设施(API、Orchestrator、envd)
- e2b-deb/E2B:客户端 SDK 与工具(Python/TS SDK、CLI)
使用案例:
- 自定义 Template,使用 e2b template build 构建,包含 Dockerfile(e2b.Dockerfile)、配置文件(e2b.toml),构建完成上传到 E2B 云端(或者子托管 GCS)
4.3.2 第一层:SDK 层(e2b-dev/E2B)
SDK 层是用户与 E2B 基础设施交互的唯一入口,负责将用户代码转换为 API 请求,并通过友好的接口封装复杂的底层通信。 E2B CLI 是基于 TypeScript 开发的命令行工具,主要用于模板管理和开发调试。 核心命令:
- e2b template build:构建 Template
- e2b template list:列出所有 Template
- e2b auth login:登录认证
构建流程:
- 本地执行 e2b template build
- CLI 读取 e2b.toml 配置文件
- 打包 Dockerfile 和上下文文件
- POST /templates → API Service
- API Service → Orchestrator → Builder Sandbox
- Docker build → rootfs.ext4 → 上传 GCS/S3
- CLI 轮询构建状态
- 返回 template_id
4.3.2.1 Template 定义与构建
Template 是 E2B 沙盒的预构建环境快照,类似于 Docker Image,但针对 Firecracker microVM 优化。
配置文件:e2b.toml
4.3.3 第二层:API 网关层(infra/api)
API 网关层是 E2B 的统一入口。它基于 Gin Web Framework 构建,提供 REST API 接口,并通过 gRPC 与 Orchestrator 通信 请求转发: 由 REST API 入口 到认证授权,处理完成之后到达请求转发,API Service 将请求转换为 gRPC 调用,转发给 Orchestrator
4.3.4 第三层:编排与控制层(infra/orchestrator)
Orchestrator 是 E2B 的大脑,负责管理所有底层资源:Firecracker 实例、网络、存储、Template 加载和沙盒生命周期。它通过 gRPC Server(端口 5008) 接收 API Service 的请求,将高层指令转化为具体的系统操作。
4.3.4.1 Firecrecker 实例管理
Orchestrator 通过 fc.Process 管理 Firecracker 进程的完整生命周期。
text启动流程: 1 生成启动脚本(StartScriptBuilder) 创建网络命名空间(ip netns) 配置 TAP 设备 和 iptables 构造 Firecracker 启动命令 2 执行 Firecracker 进程 使用 unshare -m 隔离挂载命名空间 3 通过 Unix Socket 配置 microVM ├─ PUT /boot-source (kernel 路径、启动参数) ├─ PUT /drives (rootfs 挂载) ├─ PUT /machine-config (vCPU、内存) ├─ PUT /network-interfaces (TAP 设备) └─ PUT /mmds (元数据服务) 4 启动 VM
关键点:Unix Socket 用来 Orchestrator 与 Firecracker API 通信
4.3.4.2 Template 加载与快照恢复
这是预构建的沙盒环境,Orchestrator 通过多层缓存机制优化加载速度
4.3.4.3 资源调度与生命周期管理
Orchestrator 管理两个核心资源池:NetworkPool 和 DevicePool
NetworkPool(网络池) 每个沙盒需要独立的网络环境(TAP 设备 + IP),NetworkPool 预分配资源以加速创建。
| 池类型 | 容量 | 用途 |
|---|---|---|
| 新 Slot 池 | 32 | 预创建全新的网络命名空间和 TAP 设备 |
| 复用 Slot 池 | 100 | 回收已销毁沙盒的网络资源,快速复用 |
DevicePool(NBD 设备池) rootfs.ext4 通过 NBD (Network Block Device) 挂载到 Firecracker。DevicePool 管理有限的 NBD 设备资源。
| 数 | 值 | 说明 |
|---|---|---|
| 最大设备数 | 4096 | modprobe nbd nbds_max=4096 |
| 预分配槽位 | 64 | 提前准备可用的 NBD 设备 |
| 槽位复用 | 是 | 沙盒销毁后立即回收设备编号 |
沙盒生命周期控制 Orchestrator 通过 gRPC 接口管理沙盒的完整生命周期。
textservice SandboxService { rpc Create(SandboxCreateRequest) returns (SandboxCreateResponse); // 创建 rpc Update(SandboxUpdateRequest) returns (Empty); // 更新超时 rpc Delete(SandboxDeleteRequest) returns (Empty); // 删除 rpc Pause(SandboxPauseRequest) returns (Empty); // 暂停 rpc List(Empty) returns (SandboxListResponse); // 列表 }
创建流程: Step1:API Service 发送 gRPC Create 请求 Step2:Orchestrator 接收请求(从网络池获取 Slot,从设备池获取 NBD 设备,从 TemplateCache 加载 template) Step3:初始化 rootfs(创建 NDB 设备:/dev/nbd42,连接到 rootfs.ext4,挂载为块设备) Step4:启动 Firecracker 进程,配置 kernel,rootfs,网络,MMDS, PUT /actions {"action_type": "InstanceStart"} Step5:等待 envd 就绪(envd 从 MMDS 中获取元数据,返回 sandbox_id 和连接信息)
4.3.4.4 UFFD 内存管理
Orchestrator 通过 UFFD(userfaultfd)实现快照的按需加载,这是 20-50ms 启动的关键技术。 工作流程:
text1.Orchestrator启动UFFD服务线程 2.注册内存区域(memfile) 3.Firecracker加载快照(不实际加载内存) 4.microVM启动,访问内存触发缺页 5.UFFD线程处理缺页: 从memfile读取内存页 批量加载(预测下一步需要的页) 通知KVM继续执行
效果:
- 启动时间:从 30-80ms 降到 20-50ms
- 内存节省:多个沙盒共享只读快照
- 减少缺页次数:从数千次降到数百次
4.3.5 第四层:沙盒运行时(infra/envd + Firecracker)
沙盒运行时层是用户代码真正执行的地方,由 Firecracker microVM 提供隔离环境,envd 守护进程负责与外部通信和资源管理。
4.3.5.1 envd 守护进程(文件、进程管理)
envd 是运行在 microVM 内部的 HTTP 服务,充当 Orchestrator 和用户应用之间的桥梁。
核心功能:
| 功能 | 说明 | RPC 接口 |
|---|---|---|
| 文件管理 | 读写文件、创建目录、监听文件变化 | Filesystem Service |
| 进程管理 | 启动进程、捕获输出、管理生命周期 | Process Service |
| 端口转发 | 自动将 localhost 端口暴露到宿主机 | Port Forwarder |
| 元数据获取 | 从 MMDS (169.254.169.254) 获取 sandbox_id 等信息 | MMDS Client |
技术关键点:
- Connect RPC 框架:基于 HTTP/2 的 RPC 框架,比 gRPC 更轻量
4.3.5.2 Firecracker microVM(隔离执行)
- 执行 AI 生成的代码:无法预知代码行为,需要硬件隔离
- 多租户安全:不同用户的沙盒完全隔离,攻击者无法逃逸
- 快速启动:通过快照技术,接近容器的启动速度
4.3.5.3 通信机制(HTTP over TAP)
E2B 主要使用 TAP 设备,Orchestrator Proxy 发送请求,是通过 TAP 设备转发到 microVM
TAP 设备的优势在于:
- 支持 TCP/IP,兼容所有网络工具
- 通过 iptables 控制流量(禁用 Internet、端口映射)
- envd 可以检测并转发 localhost 端口
- 可以直接使用 curl 访问沙盒内部访问
4.3.6 横向支撑:数据与存储
4.3.6.1 ProgreSQL、Redis、ClickHouse
| 存储系统 | 数据类型 | 用途 | 连接配置 |
|---|---|---|---|
| PostgreSQL | 核心业务数据 | 持久化、事务性数据 | POSTGRES_CONNECTION_STRING |
| Redis | 缓存与消息 | 高速缓存、分布式锁、PubSub | REDIS_URL / REDIS_CLUSTER_URL |
| ClickHouse | 分析数据 | 日志、监控、事件统计 | CLICKHOUSE_CONNECTION_STRING |
ProgreSQL - 核心数据库
存储内容:用户账号,团队信息,API Key(哈希),template 定义,template 构建记录,沙盒快照元数据,部署集群配置
Redis - 高速缓存与消息队列
基本上就是配合 progreSQL 的运作,缓存 key,缓存 Template 元数据,沙盒事件通知等等
4.3.6.2 Template 仓库
存储内容:Template 的二进制文件(rootfs、kernel、快照)
4.4 E2B 的核心创新
- 混合架构:构建用 Docker(易用),运行用 Firecracker(安全)
- Template 系统:用户只需写 Dockerfile,E2B 自动转换为快照
- 极速启动:20-50ms 启动 Sandbox
- 资源池化:NetworkPool、DevicePool 加速创建
- 生产级:监控、日志、多租户隔离
五、Agent 时代的沙盒选择: Docker vs Firecracker 深度对比
5.1 Agent 时代的沙盒需求
核心需求:
- 启动速度快 :用户等待时间 < 100ms,无感启动
- 持久化支持 :用户长期绑定沙盒,所有操作可持久化
- 安全隔离 :运行不可信代码,防止攻击
- 资源效率 :高密度部署,降低成本
- 易用性 :开发者友好,学习成本低
为什么这些需求很重要呢?
- Agent 需要频繁执行代码(每次对话可能执行多次)
- 用户期望即时响应(不能等待几秒)
- 代码不可信(AI 生成的代码可能有漏洞)
- 需要保留上下文(文件、环境变量、安装的包)
5.2 启动速度对比:极限在哪儿呢?
5.2.1 Docker 的启动速度
冷启动(镜像已经存在)
- docker run 命令
- 创建容器文件系统(UnionFS)
- 设置 Namespace 和 Cgroups
- 启动容器进程
时间理论上可以控制在 100 - 500 ms
热启动(Warm Pool) 基于热池分配,按用户需求进行配置已启动的容器,使用 Redis 锁确保只分配到一次。 热池启动给到速度很快,90 ms 以内,但是容器必须一直运行,持续占用,每个容器占用 CPU、内存、内核资源,需要定时检查并补充容器,这看起来没多大,但需求量一旦上去,基本相当于一整台机器都在干一件事情,维持热池的启动,这其实并不可取的,一旦大部分时间不用,沙盒容器处于空闲,会导致资源利用率极低
5.2.2 Firecracker 的启动
| 维度 | 数据 | 说明 |
|---|---|---|
| 启动速度 | 20-50ms | UFFD 按需加载 |
| VM 状态 | PAUSED | 快照是暂停状态,不占用 CPU |
| 资源占用 | 几乎为 0 | 快照只是文件,不运行 |
| 内存加载 | 按需 | Guest 访问时才加载内存页 |
| 共享 | 支持 | 多个 VM 可以共享只读快照 |
优势很明显,快照不运行,资源占用为 0,启动时才分配资源,多个 VM 可以共享只读快照,资源利用率很高,只有运行时的 VM 才占用资源
5.2.3 启动速度对比总结
| 方案 | 冷启动 | 热启动 | 代价 | 资源利用率 |
|---|---|---|---|---|
| Docker | 100-500ms | < 90ms | 容器必须一直运行 | 低(大部分时间空闲) |
| Firecracker | ≤ 125ms | 20-50ms | 快照不运行时资源占用为 0 | 高(按需分配) |
- Docker Warm Pool:用"空间换时间"(预创建运行的容器)
- Firecracker 快照:用"智能加载换时间"(UFFD 按需加载)
- Firecracker 更优:启动更快(20-50ms vs < 90ms),资源利用率更高
5.2.4 为什么 Docker 必须一直运行?
问题:为什么 Docker Warm Pool 的容器必须一直运行(state: STARTED)? 答案:因为 Docker 容器的"状态"是进程状态,停止 = 进程退出 = 状态丢失
Docker 容器的本质:
- 容器 = 进程 + Namespace + Cgroups
- 容器的"运行"= 进程在运行
- 容器的"停止"= 进程退出
问题:进程退出后会发生什么?
- 内存被释放(所有变量、缓存丢失)
- 文件描述符关闭(网络连接断开)
- 进程状态丢失(无法恢复到停止前的状态)
Docker 的困境:
- 如果容器停止 → 下次启动需要重新初始化(100-500ms)
- 如果容器一直运行 → 资源一直占用(浪费)
- 两难:要么慢,要么浪费
为什么 Docker Commit 不能解决问题?
- docker commit 只能保存文件系统
- 不能保存内存状态(变量、缓存)
- 不能保存进程状态(打开的文件、网络连接)
- 下次启动仍需要重新初始化
→ Docker 的本质限制:容器 = 进程,进程停止 = 状态丢失
5.2.5 为什么 Firecracker 可以暂停?
答案:因为 Firecracker 是 VM,可以保存完整的"机器状态"
VM 的本质:
- VM = 虚拟机器(有 CPU、内存、设备)
- VM 的"运行"= 虚拟 CPU 在执行指令
- VM 的"暂停"= 虚拟 CPU 停止,但状态保留
Firecracker 快照保存了什么?
- memfile:完整的 Guest 内存(所有变量、缓存、进程状态)
- vmstate:vCPU 寄存器(程序计数器、栈指针)
- vmstate:设备状态(网络、磁盘)
- rootfs:文件系统
为什么 Firecracker 恢复这么快?
- 因为 Guest Kernel 已经启动过了(保存在快照里)
- 因为应用已经初始化过了(保存在内存里)
- 恢复 = 直接继续执行(不需要重新初始化)
5.3 持久化支持对比:谁更适合长期绑定?
5.3.1 场景:用户长期绑定一个沙盒
text需求: day1:安装 numpy,playwright,pandas,chromium。 day2:创建某平台爬虫脚本 day3:运行分析脚本 day4:创建新的工具功能,比如cookie ...
要求:所有操作持久化(文件、环境变量、安装的依赖),随时可恢复,绝对不能丢失数据
5.3.2 Docker 的持久化方案
方案一 :容器一直运行 优势:简单,无需额外操作 劣势:很明显,会造成资源浪费,成本高,不稳定(容器可能会崩掉) 方案二 :使用 Docker Volume 优势:数据只能持久化在宿主机,容器停止数据不会丢失 劣势:只能持久化指定目录,环境变量、安装的包不会保留,需要手动配置 Volume 方案三 :Docker Commit(Daytona 的方案)
textfunc (d *DockerClient) Commit(ctx context.Context, sandboxId string) error { // 将运行中的容器commit为新镜像 _, err := d.client.ContainerCommit(ctx, sandboxId, types.ContainerCommitOptions{ Reference: fmt.Sprintf("sandbox-%s:latest", sandboxId), Pause: true, // 暂停容器 }) return err }
流程:
- 用户使用沙盒(安装包、创建文件)
- 用户停止沙盒
- Daytona 执行 docker commit
- 生成新镜像(包含所有修改)
- 下次启动时,使用新镜像
优势:所有修改都保留,容器可停止,不占用资源 劣势:commit 很慢(需要保持整个文件系统),镜像根据用户需求会越来越大,每次修改均增大,启动会越来越慢,存储成本
5.3.3 Firecracker 的持久化方案
快照: 我们基于 E2B 的处理方式来看 流程:
- 用户使用沙盒(安装包、创建文件)
- 用户停止沙盒
- E2B 创建快照(memfile + vmstate + rootfs)
- 上传到对象存储(S3/GCS)
- 下次启动时,加载快照(20-50ms)
优势:
- 所有修改都保留(内存、文件系统、进程状态)
- 快照创建快(暂停 VM 即可)
- 启动快(20-50ms,UFFD 按需加载)
- 增量快照(只保存变化部分,节省存储)
- Copy-on-Write(多个 VM 共享只读部分)
劣势(但其实 E2B-dev/info 已经提供了解决方案):
- 需要对象存储(S3/GCS)
- 实现复杂(需要 UFFD、NBD 等技术)
5.3.4 汇总
| 方案 | 持久化方式 | 恢复速度 | 存储成本 | 资源占用 |
|---|---|---|---|---|
| Docker 一直运行 | 自然保留 | 0ms | 低 | 高(一直占用) |
| Docker Volume | 部分持久化 | 100-500ms | 低 | 低(停止时) |
| Docker Commit | 完整持久化 | 100-500ms | 高(镜像大) | 低(停止时) |
| Firecracker 快照 | 完整持久化 | 20-50ms | 中(增量) | 低(停止时) |
5.4 为什么 Firecracker 更适合 Agent 时代呢?
5.4.1 Docker Warm Pool 的本质问题
- 资源浪费
Warm Pool 创建的 N 个运行的容器,资源会持续占用
- 扩展性差 a. 若用户持续增加,内存就会一直增加,直到增加到一个天文数字,这其实就是侧面表示 Docker Warm Pool 本身就是不适合大规模部署的 b. 共享内核的风险 用户的数量持续增加,这就代表共享内核的容器会大大增加,这就会出现一个很致命的问题,一个容器逃逸,会牵连影响所有容器,一个容器泄露,会影响所有容器
5.4.2 Firecracker 快照的优势
- 资源可按需分配
快照 = 暂停状态的 VM,不运行,资源利用率理论上是可以达到百分百
- 扩展性好
若增加用户数量,比如 10000 个,只会占用我们的磁盘内存,并且只有 VM 运行的适合才占用内存,成本可控
- 硬件级别隔离
每个 VM 独立内核,每个 VM 组件不受干扰
5.4.3 Agent 时代的选择
团队内部(5 - 100 人) 可选择 Docker Warm Pool,原因很简单,简单易用,成本可靠,且易维护,并且可以充分信任 多租户平台,给到广大群众使用 Firecracker 快照,资源利用率高,成本可控,安全性高,扩展性好 AI Agent 平台(未来我们的百万甚至千万用户) Firecracker 快照(这是唯一选择)