目录
第一部分:起跑线 —— 五分钟读懂 RAG
检索增强生成(RAG)作为一种结合信息检索与文本生成的技术,已成为解决大语言模型(LLM)"知识过时"和"幻觉输出"问题的关键方案。简单来说,RAG 通过将外部知识库与 LLM 生成能力相结合,使模型能够基于真实、最新的信息输出答案。
1. 为什么我们需要 RAG?
在 RAG 出现之前,大模型的应用开发主要依赖提示工程和模型微调,但二者都有明显局限:
- 提示工程:适合简单指令,但无法补充模型未训练过的新知识(如企业内部文档),且受限于上下文窗口长度。
- 模型微调:能注入新领域知识,但成本高(需大量标注数据+算力)、更新慢(改一次就要重新训一次),且容易遗忘原有能力。
RAG 的核心价值,就是做大模型的“外置知识库”——无需微调,只需通过实时检索外部文档,就能让模型生成更精准、更实时、更合规的答案。
如果把大模型比作一个超级学霸,但他记性不好且知识停留在两年前;那么 RAG 就是给他发了一本随时可查的“参考书”,让他能够进行 “开卷考试”。
2. RAG 架构的三步曲
RAG 核心流程
RAG 系统的核心流程可概括为"先检索、后生成",主要分为三个关键环节:索引构建、检索和生成。
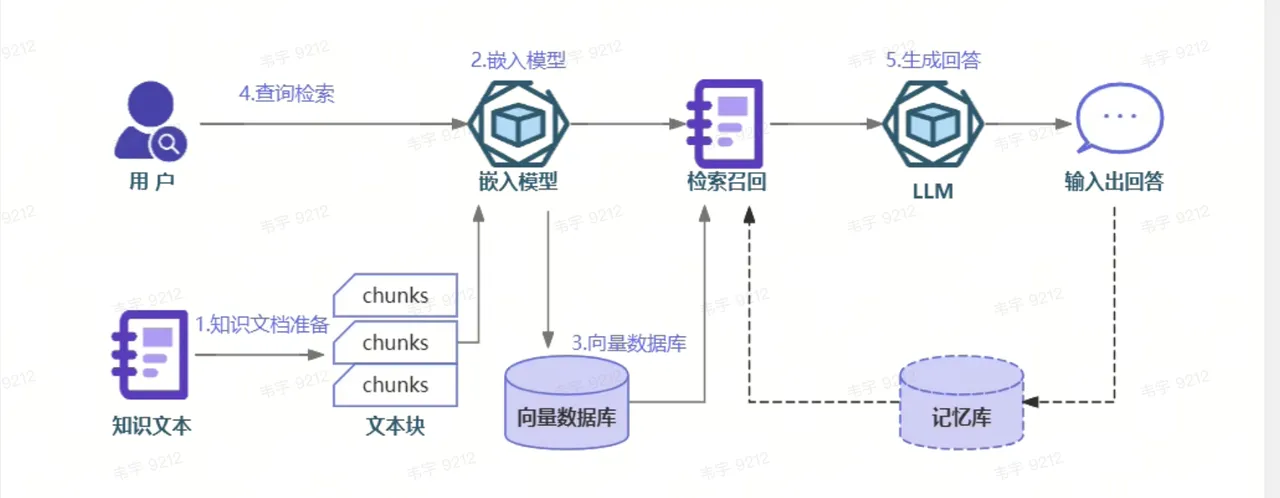
- 索引构建 (Indexing):把文档切碎(Chunking),变成向量(Embedding),存进向量数据库。
- 检索 (Retrieval):当用户提问时,系统在数据库中找到最相关的片段。
- 生成 (Generation):将用户的问题 + 找到的片段一起喂给大模型,生成最终答案。
💡 写在起跑线之后
听起来很简单?确实,写个 Python 脚本调用一下 LangChain,你可能只需要 5 分钟就能跑通上述流程。
但是,当你把它上线到生产环境,你会发现效果一塌糊涂:搜不到、答不准、甚至答非所问。这时候,你才刚刚跑出起跑线,离真正的终点还差十公里。
第二部分:那十公里 —— 决定成败的关键细节
真正的 RAG 护城河,不在于你用了哪个最先进的大模型,而在于你如何处理那些隐藏在冰山之下的脏活、累活。下面我们将深入这“最后十公里”,看看在实际工程中,我们会遇到哪些具体的痛点,以及如何优雅地解决它们。
第一公里:数据的“肮脏”现实 (Data Governance)
在 Demo 阶段,我们通常使用干净的 .txt 或 .md 文件进行测试,效果往往出奇的好。但在现实的企业级应用中,数据往往是脏乱差的。为了让 RAG 吃得健康,我们需要建立一套分层的数据治理体系。
第 1 层:物理层 —— 攻克格式壁垒 (Physical Layer)
这是数据“进门”的第一步。RAG 面临的最大敌人往往是 PDF 和图片。
- 痛点:PDF 是为打印而生的。如果你简单提取文本,表格会乱序("姓名 | 年龄" 变成 "姓名年龄"),多模态信息会丢失(流程图、架构图被直接忽略)。
- 对策:建立重型的 ETL 流水线。引入 OCR 或多模态大模型(如 Gemini 1.5 Pro, GPT-4o)来“看”文档,将 PDF 页面直接转换为 Markdown,保留标题层级和表格结构,并清洗掉页眉、页脚等噪音。 在业界,Unstructured.io 是处理此类问题的标杆工具,它能将复杂的多栏 PDF 精准转换为 JSON;而 LlamaIndex 推出的 LlamaParse 则专门针对财务报表优化,能有效防止模型因表格数据乱序而产生幻觉。
第 2 层:语义层 —— 清洗与归一化 (Semantic Layer)
即便文字提取出来了,如果不进行语义层面的治理,RAG 依然会变成“人工智障”。
- 文本归一化 (Normalization):解决“同义不同词”的痛点。
- 场景:文档 A 写的是“LLM”,文档 B 写的是“大语言模型”。如果不统一,用户搜“大模型”可能就漏掉了文档 A。
- 对策:在入库前建立术语表,将所有变体统一替换为标准术语。
- 去重与纠错:
- 场景:企业里充斥着《V1 版》、《V2 修订版》、《V2 最终版》。如果不去重,重复文档会挤占宝贵的 Top-K 检索窗口。
- 对策:利用 Hash 算法去重,并引入拼写检查模型修复 OCR 带来的错别字。
第 3 层:认知层 —— 增强与维护 (Cognitive Layer)
⚠️ 注意:这一层并非通用标准,而是针对特定业务场景(如新闻、政策、高频更新数据)的进阶优化。
如果你的数据是静态的(如历史典籍),前两层足矣;但如果你的数据是动态的,这一层至关重要。
- 时效性管理 (Time Sensitivity):
- 痛点:用户问“最新政策”,RAG 却自信地甩出了一份 2018 年的废止文件。
- 对策:必须提取文档的生效时间作为元数据 (Metadata)。在检索时,通过时间衰减函数对旧文档降权,或者直接过滤掉失效文档。
- 反馈闭环 (Feedback Loop):
- 痛点:错误的文档一直留在库里坑人。
- 对策:建立“点踩”机制。利用用户的反馈数据来标记脏数据,定期从库中清除或修正这些“有毒”知识。 以 BloombergGPT (彭博社) 为例,他们在构建金融大模型时,建立了严格的时间戳标记(Time-stamping)系统,确保模型不会混淆 2008 年金融危机的数据和现在的行情,这已成为高时效性 RAG 数据治理的教科书级范例。
第三公里:切分的艺术 (Chunking Strategy)
把文档切成块(Chunk)是 RAG 的基本功,但很多开发者低估了切分策略对检索效果的毁灭性影响。
1. 语义断裂的悲剧
假设你采用最简单的“按 500 字符切分”策略,一句话可能会被生硬地切成两半:
- Chunk A:“根据公司最新的规定,所有员工的年终奖发放标准是——” (结尾)
- Chunk B:“——基于当年的 KPI 绩效考核,且系数调整为 1.2。” (开头)
- 后果:当用户问“年终奖发放标准是什么?”时,Chunk A 因为只有主语没有宾语,相关性低;Chunk B 因为只有宾语没有主语,相关性也低。两个关键片段都可能因为语义不完整而落选 Top K,导致模型回答“未找到相关信息”。
2. 为什么现在的模型还需要切分?
你可能会问:“现在的模型都能读 100 万字了,为什么还要切分?”
这涉及到一个信噪比的问题。如果你为了回答“某员工的工号是多少”,而把整本《员工手册》都塞给模型:
- 干扰:模型可能会被手册中其他相似名字员工的信息干扰(Lost in the Middle 现象)。
- 成本与延迟:处理 10 万 Token 的延迟和费用,是处理 500 Token 的几百倍。切分是为了让模型聚焦于最关键的证据,而非让它在大海捞针。
💡 怎么切才科学?
- 递归分块 (Recursive Splitting):这是目前最推荐的通用策略。它像剥洋葱一样,优先尝试用“段落换行符”切分,如果段落太长,再尝试用“句子句号”切分。这样最大程度保留了段落的完整语义。这也正是 LangChain 框架中默认推荐的
RecursiveCharacterTextSplitter策略,是目前大多数企业级 RAG 应用在生产环境中的首选。 - 滑动窗口 (Sliding Window):在每个 Chunk 的首尾保留 10%-20% 的重叠内容(Overlap)。比如 Chunk A 的结尾 100 字,会重复出现在 Chunk B 的开头。这就像接力赛的交接棒区,确保没有任何一句话会被切断,保证了语义的连续性。
- 基于模型的语义切分 (Semantic Chunking):这是进阶玩法。利用 BERT 等小模型计算前后句子的语义相似度。如果相邻两句的相似度骤降(比如从讲“产品功能”突然跳到“售后服务”),就在这里切一刀。这种方式能保证每个 Chunk 内部讨论的话题高度统一,检索准确率往往最高。例如 IBM watsonx.ai 平台就明确支持这种技术,用于处理复杂的法律合同和技术手册,有效防止了“断章取义”。
第五公里:检索不只是“找相似” (Advanced Retrieval)
很多初学者以为 RAG 就是“向量搜索 (Vector Search)”,其实向量搜索有一个致命的弱点:它懂语义,但不懂精确匹配。
1. 向量搜索的“盲区”
向量搜索计算的是语义相似度。
- 场景:用户搜“Q3 财报”。
- 向量库的反应:它可能会觉得“Q3”这个词太短,语义不明显,于是找来了一堆“财务报告”、“年度总结”、“第三季度展望”等语义接近的文档。
- 问题:用户其实非常明确就要包含 "Q3" 这个关键词的文档,而不是其他季度的。向量模型可能会因为“过度联想”而忽略了精确的字面匹配。
2. 召回与精排的漏斗
单纯依赖 Top K 检索往往存在“不仅漏得快,而且不准”的问题。我们需要一个漏斗机制。
💡 进阶方案:
- 混合检索 (Hybrid Search):这是现代 RAG 的标配。 一路用 Vector Search(抓语义),一路用 BM25 / Keyword Search(抓关键词),最后通过加权算法(RRF)合并结果。这样既能懂“苹果”和“水果”是相关的,也能精准定位到“iPhone 15 Pro”这个具体型号。目前 Elasticsearch 和 MongoDB Atlas 等主流数据库都在最新版本中原生集成了这种混合检索功能,方便企业直接复用基础设施。
- 重排序 (Rerank) —— 必不可少的修正: 这是提升准确率最立竿见影的手段。先用成本较低的混合检索海选出 50 条大概相关的文档,再引入一个专门的 Rerank 模型(Cross-Encoder)像阅卷老师一样逐一精细打分,把真正匹配的提拔到前面。在实际生产中,Cohere Rerank 是这一领域的标杆方案,许多企业(如 Notion、Oracle)并没有从头训练模型,而是直接接入 Cohere 的 API 来“清洗”检索结果,用极低的成本换取了检索精度的显著提升。
第六公里:未来的探索 —— GraphRAG 的结构化视野
这一公里目前并不是所有 RAG 系统的“必选项”,而是业界为了解决传统 RAG 瓶颈正在积极探索的一个前沿方向。当你的应用场景对“复杂推理”和“全局理解”有极高要求时,这是一个非常值得关注的思路。它是 RAG 技术从“概率性匹配”向“结构化推理”的一次重要跃迁。
1. 向量检索的“语义孤岛”困境
传统的 RAG 架构主要依赖于向量嵌入(Vector Embeddings)技术。这种方法在处理“显性事实检索”任务(如“公司的年收入是多少?”)时表现出色,但在面对需要全局理解或跨文档推理的复杂问题时,往往显得力不从心。
- 缺失的逻辑链条:向量数据库本质上存储的是非结构化的数据片段。尽管嵌入向量捕捉了语义信息,但它无法显式地保留实体之间的逻辑关系、因果链条或层级结构。
- Connecting the Dots(连接点滴)的难题:当用户提出的问题需要串联多个线索时——例如,“分析过去三年来地缘政治变化对该供应链网络的累积影响”——向量 RAG 往往只能检索到包含相关关键词的零散片段,而无法构建出贯穿多个文档的完整叙事逻辑。这种现象被称为**“语义孤岛”**效应:信息虽然被检索到了,但其背后的结构化语境丢失了。
- 全局性查询(Global Queries)的挑战:面对“该数据集的主要主题是什么?”这样的宏观问题,向量检索很难确定哪些具体的文本块能代表整体,往往导致检索结果的片面性或对大量 Token 的无效消耗。
2. GraphRAG 的核心理念:结构化认知的引入
GraphRAG(Graph-based Retrieval-Augmented Generation)的核心理念在于利用大语言模型的能力,在检索之前先对语料库进行深度的“理解”和“重组”。它不满足于仅仅存储原始文本片段,而是通过提取文本中的实体(Entities)、关系(Relationships)和关键声明(Claims),构建出一个高密度的知识图谱(Knowledge Graph, KG)。
这种结构化认知的引入,使得系统具备了以下传统 RAG 无法比拟的能力:
- 全景式理解(Holistic Understanding): 通过对图谱进行社区检测(Community Detection),系统能够自底向上地生成各个层级的摘要。这使得 GraphRAG 能够像人类专家一样,先把握宏观图景,再深入微观细节,从而具备回答“这份文档讲了什么故事?”这类全局性问题的能力。
- 多跳推理(Multi-hop Reasoning): 知识图谱的拓扑结构允许系统沿着关系路径进行遍历(例如:实体 A 影响 实体 B,实体 B 导致了 事件 C,因此 A 是 C 的潜在诱因)。这能发现那些在文本上距离较远、甚至分布在不同文档中,但逻辑上紧密相连的隐含信息。
- 可解释性与溯源(Explainability & Provenance): 生成的每一个答案都可以追溯到具体的实体节点、关系描述以及支撑这些关系的原始文本单元,极大地增强了结果的可信度,避免了黑盒模型“一本正经胡说八道”的风险。
目前,微软研究院开源的 GraphRAG 是这一方向的标杆项目。在处理数百万字的复杂文档(如私有财报、法律卷宗)时,它展示了比传统 Baseline RAG 更强大的归纳和推理能力,特别是能够回答“这些文件共同揭示了什么隐患?”这类高级问题。
如果对 GraphRAG 有兴趣进一步了解的,这里我推荐一篇深入浅出的文章来进一步阅读了解《超越传统 RAG:GraphRAG 全流程解析与实战指南》
第七公里:RAG 的进阶应用 —— 成为 Agent 的工具
这其实已经不完全属于 RAG 架构本身的范畴,而是 RAG 的一种高级使用方式。在更复杂的场景中,RAG 不再是一个独立的问答系统,而是被集成到 AI Agent (智能体) 中,作为一个 “知识获取工具” 。
传统的 RAG 流程是死板的:用户提问 -> 检索 -> 回答。如果你问一个需要多步推理的问题,比如“比较 A 公司和 B 公司 2023 年的营收增长率”,传统 RAG 可能会一次性搜出一堆乱七八糟的财报片段,然后试图强行总结,结果往往是混乱的。
💡 Agentic RAG 的工作流:
像 UltraRAG 这样的项目,本质上就是将 RAG 封装为一个可以被调用的工具(Tool)。
-
主动规划 (Planning):
Agent 接收到问题后,会先思考:“要回答这个问题,我需要先查 A 公司的财报,再查 B 公司的财报,最后做计算。”
-
按需调用 (Tool Use):
- Step 1: Agent 调用 RAG 工具,搜索“A 公司 2023 营收”。
- Step 2: Agent 再次调用 RAG 工具,搜索“B 公司 2023 营收”。
- Step 3: Agent 拿到两份确凿的数据后,自己进行计算和对比。
-
自我反思 (Self-Correction):
如果第一次检索结果为空,Agent 不会直接回复“不知道”,而是会像人一样反思:“可能是关键词不对”,然后尝试换个关键词再次搜索。
这种结合让 RAG 从“死板的流程”变成了“灵活的技能”。在 C 端,Perplexity.ai 就是这种模式的典型代表,它会主动显示检索源甚至修正查询词;而在开发侧,LangGraph 则是目前构建此类“多跳问答(Multi-hop QA)”系统的核心框架,广泛应用于金融研报分析等复杂场景。
第九公里:拒绝“盲人摸象” —— 科学评测 (Evaluation)
一切没有评测的优化都是“玄学”。在 RAG 上线前的最后一公里,你必须建立一套自动化的评测体系,否则你永远不知道改了一个 Prompt 是变好了还是变坏了。
1. 评什么? (The Metrics)
业界通用的 RAG 评测维度主要包括 RAG Triad(三元组):
- Context Relevance (上下文相关性):检索出来的片段真的和问题有关吗?
- Groundness / Faithfulness (忠实度):AI 的回答是基于检索到的片段生成的,还是它自己瞎编的?
- Answer Relevance (答案相关性):AI 的回答真的解决用户的问题了吗?
2. 怎么评? (The Tools)
靠人工看 Log 是不可能的。你需要使用 “LLM-as-a-Judge” 模式,即用一个更强的模型(如 GPT-4)来给你的 RAG 系统打分。在这一领域,Ragas 是目前最流行的开源框架,它能通过自动生成测试集来计算各项指标分数;而 TruLens 则提供了可视化的“反馈三元组”仪表盘,帮助开发者快速定位到底是检索(Retrieval)出了问题,还是生成(Generation)出了问题。
第三部分:最后一公里 —— 认知的升级
当我们解决了数据清洗、分块策略、混合检索、图谱增强、Agent 集成以及科学评测后,我们终于来到了最后一公里。这不仅是技术的完善,更是对 RAG 角色定位的重新认知。
RAG 的角色演变:从“插件”到“海马体”
在 RAG 刚出现时,我们把它看作一个 “增强包” (Plugin),只有在用户提问需要查资料时才触发,就像考试时偶尔翻一下书。
但现在,随着 AI Agent 的兴起,RAG 正在成为 AI 系统的 “基础设施”,或者更准确地说,它变成了 AI 的 “海马体” (长期记忆)。
- 以前的视角:我是一个聊天机器人,我外挂了一个知识库。
- 现在的视角:我是一个智能体,我有完整的记忆系统。
场景的质变:
现在的高级应用中,RAG 不再仅仅用来回答“公司规章制度是什么”这种静态问题。
- 当 AI 写代码时,它通过 RAG 自动“回忆”起项目之前的代码风格和你昨天的需求变更;
- 当 AI 做计划时,它自动“参考”团队历史项目的复盘教训。
它不再是一个需要你显式调用的功能,而是变成了 AI 思考过程中的本能反应,是 AI 系统中不可或缺的文件系统 (File System)。
结语
五分钟读懂 RAG 并不难,难的是如何不再把它当做一个简单的“搜索工具”,而是把它构建成 AI 系统中可靠的“长期记忆体”。
当你不再满足于“系统跑通了”,而是愿意从数据清洗的脏活干起,为 1% 的检索准确率去反复打磨切分策略、引入知识图谱、构建自动化评测时,你就真正填平了这最后的十公里,把 RAG 从一个技术玩具变成了企业的核心生产力。
面试锦囊 —— 如何体现你对 RAG 的深度理解
当面试官问你:“谈谈你对 RAG 的理解”时,不要只背诵“检索增强生成”这个定义。你可以尝试从以下三个维度来回答,展示你的实战经验和技术视野。
1. 宏观定位:从“外挂”到“记忆” “我认为 RAG 不仅仅是大模型的外挂知识库,它本质上是 AI 系统的长时记忆体 (Long-term Memory)。它解决了 LLM 训练后知识固化的问题,让我们能以极低的成本将私有数据注入到生成过程中,解决了幻觉和时效性痛点。”
2. 工程落地:魔鬼在细节 “很多 Demo 跑通了就结束了,但我的经验是,RAG 的护城河在于 ‘最后十公里’的数据治理和检索优化。
- 比如在数据侧,PDF 的表格还原和语义切分(Chunking)质量直接决定了检索上限;
- 在检索侧,单纯的向量检索往往不够用,必须引入混合检索 (Hybrid Search) 和 重排序 (Rerank) 机制,才能在高召回的基础上保证高准确率。”
3. 前沿趋势:Agent 与 Graph “此外,我也关注到 RAG 正在向 Agentic RAG 演进。它不再是死板的流水线,而是 Agent 手中的工具,可以通过自我反思(Self-correction)来优化检索结果。同时,GraphRAG(知识图谱)的出现,也很好地解决了传统 RAG 难以处理全局性推理的问题。”
面试官:请谈谈你对 RAG 的理解?
“我觉得可以从三个维度来看 RAG。
首先,从架构定位上看,我认为 RAG 是大模型的长时记忆体(Long-term Memory)。它解决了模型训练后知识固化的问题,让我们能以极低的成本将私有数据注入到生成过程中,本质上是把 LLM 的‘内存’变成了‘外存’,解决了幻觉和时效性问题。
其次,在工程落地上,我认为 RAG 的门槛不在于跑通流程,而在于**‘最后十公里’的精度打磨**。 在实际项目中,我发现单纯的向量检索(Vector Search)往往不够用,因为向量懂语义但不懂精确匹配(比如工号、专有名词)。所以,我会采用混合检索策略,结合 BM25 关键词检索,并且在召回后必须引入 Rerank(重排序) 机制,这能显著提升 Top-K 的准确率。 另外,数据治理是被很多人忽视的一环。PDF 的表格还原、文档的语义切分(Chunking),这些脏活的处理质量直接决定了检索的上限。
最后,从发展趋势看,我关注到 RAG 正在向 Agentic RAG 演变。 传统的 RAG 是死板的流水线,而现在的 RAG 更像是一个 Agent 的工具(Tool)。Agent 可以通过自我反思(Self-correction)来判断一次检索够不够,不够就换个词再搜,或者通过 GraphRAG(知识图谱)来解决跨文档的全局性推理问题。
所以总结来说,RAG 始于检索,成于数据细节,终于智能体架构。”