目录
 本文主要意在通过这道面试 SQL 题目讲解描述 MySQL 中索引的本质——索引B+树。所以文章通过拆解这个问题,一步步分析构建起来 MySQL 中的索引 B+ 树。
本文主要意在通过这道面试 SQL 题目讲解描述 MySQL 中索引的本质——索引B+树。所以文章通过拆解这个问题,一步步分析构建起来 MySQL 中的索引 B+ 树。
引言:索引的本质与B+树
在MySQL中,索引是数据库性能优化的核心手段。而索引的底层数据结构,决定了我们如何设计和使用它。MySQL默认的存储引擎InnoDB使用的是B+树作为索引的底层数据结构。
B+树是一种多路平衡搜索树,它在保持查询效率的同时,特别适合磁盘存储和范围查询。在B+树中,所有数据记录都存储在叶子节点,而非叶子节点只存储索引键值,这使得B+树具有良好的磁盘I/O效率。
在本文中,我们将通过一个具体的SQL查询问题,深入探讨B+树的原理,以及如何基于B+树特性设计最优索引。
问题拆解:索引设计的三个子问题
先来分析这个SQL查询:
sqlSELECT * FROM table
WHERE a = 1 AND b > 2
ORDER BY c, d, f;
这个问题可以拆解为三个子问题:
- a,b怎么建索引?
- c,d,f怎么建索引?
- (a,b) + (c,d,f)怎么建索引?
接着我们通过对这三个子问题分析解答,来回答我们的索引题。
问题一:a,b怎么建索引?B+树联合索引结构 & 最左匹配原则解析
在我们对a,b讨论如何建立索引时,其实问题就是在(a, b)和(b, a)之间进行讨论选择,所以我们的问题就是这两个索引究竟哪个更适合题目的要求?为什么适合?
(a, b)和(b, a)怎么选?
在对两者进行讨论前,我们需要先建立起两者的索引,假设我们建立如下联合索引:
sqlCREATE INDEX idx_ab ON table(a, b);
CREATE INDEX idx_ab ON table(b, a);
-
B+树联合索引的结构(使用Graphviz描述):

dotdigraph BPlusTree { node [shape=plaintext]; rankdir=TB; // 根节点 root [label="Root\n(a=1, b>2)"]; // 内部节点 internal1 [label="Internal Node\n(a=1)"]; internal2 [label="Internal Node\n(a=1, b=2)"]; // 叶子节点 leaf1 [label="Leaf Node\n(a=1, b=3)\nData: [row1, row2, ...]"]; leaf2 [label="Leaf Node\n(a=1, b=4)\nData: [row3, row4, ...]"]; leaf3 [label="Leaf Node\n(a=1, b=5)\nData: [row5, row6, ...]"]; // 关系 root -> internal1; internal1 -> leaf1; internal1 -> leaf2; internal1 -> leaf3; }
B+树结构说明:在叶子节点中,数据按
(a, b)的顺序存储。当查询a=1 AND b>2时,数据库可以快速定位到a=1的叶子节点,然后在该节点内扫描b>2的数据。
为什么(a, b)比(b, a)更好?——B+树的局部有序性原理
本质上(a, b)和(b, a)两种索引并没有谁优于谁的说法,而且受限于我们使用索引的 SQL 语句决定性能优异的,在 where a = 1 and b > 2 中,两者的区别如下:
| 索引 | WHERE条件 | 效率 | 说明 |
|---|---|---|---|
| (a, b) | a=1 AND b>2 | 高 | a=1可以快速定位,b>2可以在a=1的范围内扫描 |
| (b, a) | a=1 AND b>2 | 低 | b>2可以快速定位,但a=1无法利用索引,必须回表过滤 |
B+树的局部有序性原理
为什么会出现这种情况呢?这就需要引出 B+ 树局部有序性这个关键的概念了。
对于这块内容,是本文的重中之重之重之重的重点!!!!!!由于篇幅过大,且还是较为独立的内容,因此我单独抽出文章详细梳理讲解。请转你真的懂 B+ 树吗?你真的懂 MySQL 索引长什么样吗?详细阅读!
问题二:c,d,f怎么建索引?举一反三
现在,我们考虑如何为c,d,f建立索引,以支持ORDER BY c, d, f。想要解决这个问题,我们需要深入了解回表查询和文件排序这两个概念,以及它们是如何影响数据库查询性能的。
覆盖索引:避免回表查询
首先,让我们探讨如何通过创建合适的索引来避免回表查询。假设我们的查询是:
sqlSELECT c, d, f FROM table WHERE a = 1 AND b > 2 ORDER BY c, d, f;
索引分类
在 MySQL 中存在者多种索引,根据是否聚簇数据分为主键索引和普通索引。
主键索引,也是聚簇索引,在 MySQL 的 B+ 索引树的叶节点,是直接存储具体的行数据。在创建表时自动创建,组织表中的数据在 MySQL 数据库中存储,用于支持所有的数据查找,保证提供查找功能。
而普通索引,也就是非聚簇索引,在 MySQL 中就是我们平常根据对应字段创建的索引,用于辅助 SQL 语句查找,能对特定的 SQL 语句起到优化提速的效果。不同于主键索引,这些普通索引的叶节点通常是存储一个指向数据具体位置的指针(MySQL 中通过存储主键ID实现指针效果),而这个通过指针获取真正数据的过程就是回表查询。
然后在这个我们创建的普通索引 B+ 树中,节点存储的 Value 就是我们的字段值。也就是说,在我们索引树中,存在者我们需要的字段值。这样,我们就可以在通过主键 ID 到磁盘中获取一行的数据前,提前获取到对应字段的值。
而当我们创建一个包含所有这些字段的联合索引(c, d, f),也就是覆盖索引。那么MySQL可以使用这个索引来满足查询中的WHERE条件和SELECT子句的需求,而无需访问数据表本身,也就实现避免回表查询。
a=1 AND b>2可以直接利用索引来定位符合条件的记录。SELECT c, d, f所需的字段都包含在这个索引中,因此不需要再回到主表获取额外的数据。
B+树索引与排序
在解决了回表查询的问题后,我们继续深入,探讨如何进一步优化查询性能——避免文件排序(filesort)。
我们知道,MySQL在执行ORDER BY时,如果无法利用索引的顺序,就会触发filesort机制:将结果集取出后,在内存或磁盘中进行排序。这不仅消耗CPU资源,还可能导致磁盘I/O,严重影响性能。
那么,如何让MySQL跳过filesort,直接“按序输出”呢?
索引的有序性:排序的“天然加速器”
B+树索引天生是有序的。它的叶子节点通过双向链表连接,并按索引键的字典序排列。因此,只要查询的排序顺序与索引的顺序一致,MySQL就可以直接利用索引的物理顺序返回数据,无需额外排序。
为什么(c, d, f)比(f, d, c)更好?
我们来对比两种索引设计:
(c, d, f):
索引的排序顺序是c → d → f,与ORDER BY c, d, f完全一致。MySQL只需从索引的起始位置开始顺序扫描,即可获得有序结果,避免filesort。同时,由于c,d,f都在索引中,也避免了回表。(f, d, c):
索引的排序顺序是f → d → c,而查询要求按c, d, f排序。索引中c是最后一个字段,无法形成c,d,f的全局有序。MySQL必须先取出所有数据,再进行filesort,无法利用索引排序。即使字段都在索引中,仍需filesort。
B+树结构对比
下面用Graphviz展示(c, d, f)和(f, d, c)索引的B+树结构:
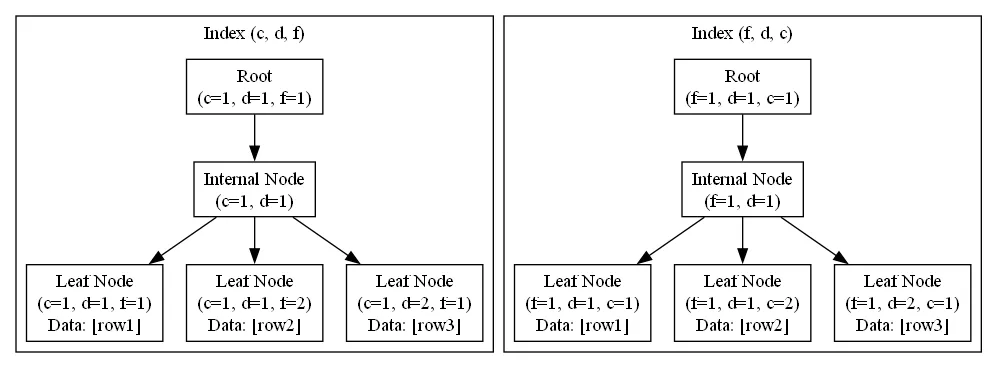
dotdigraph BPlusTree { node [shape=plaintext]; rankdir=TB; // (c, d, f) 索引 subgraph cluster_cdf { label="Index (c, d, f)"; cdf_root [label="Root\n(c=1, d=1, f=1)"]; cdf_internal [label="Internal Node\n(c=1, d=1)"]; cdf_leaf1 [label="Leaf Node\n(c=1, d=1, f=1)\nData: [row1]"]; cdf_leaf2 [label="Leaf Node\n(c=1, d=1, f=2)\nData: [row2]"]; cdf_leaf3 [label="Leaf Node\n(c=1, d=2, f=1)\nData: [row3]"]; cdf_root -> cdf_internal; cdf_internal -> cdf_leaf1; cdf_internal -> cdf_leaf2; cdf_internal -> cdf_leaf3; } // (f, d, c) 索引 subgraph cluster_fdc { label="Index (f, d, c)"; fdc_root [label="Root\n(f=1, d=1, c=1)"]; fdc_internal [label="Internal Node\n(f=1, d=1)"]; fdc_leaf1 [label="Leaf Node\n(f=1, d=1, c=1)\nData: [row1]"]; fdc_leaf2 [label="Leaf Node\n(f=1, d=1, c=2)\nData: [row2]"]; fdc_leaf3 [label="Leaf Node\n(f=1, d=2, c=1)\nData: [row3]"]; fdc_root -> fdc_internal; fdc_internal -> fdc_leaf1; fdc_internal -> fdc_leaf2; fdc_internal -> fdc_leaf3; } }
为什么(c, d, f)可以避免filesort?
在(c, d, f)索引中,数据在叶子节点中严格按 c → d → f 的顺序排列。当执行 ORDER BY c, d, f 时,MySQL只需按链表顺序读取叶子节点,即可获得有序结果,无需任何额外排序操作。
而在(f, d, c)索引中,数据按 f → d → c 排列。例如:
(f=1, d=1, c=1)(f=1, d=1, c=2)(f=1, d=2, c=1)
如果按 c, d, f 排序,c=1 的记录应该在 c=2 之前,但它们在索引中是分散的。MySQL无法通过一次顺序扫描获得有序结果,必须进行filesort。
重要提示:在MySQL中,若要同时避免回表查询和文件排序,需确保:
- 查询字段是索引的子集(覆盖索引)
ORDER BY字段与索引的最右前缀一致
这样,MySQL才能“一站式”完成查找、取值、排序,实现最优性能。
问题三:(a,c,d,f,b) 联合索引:索引下推与局部有序性
我们先回到需要优化的完整 SQL 查询:
sqlSELECT * FROM table
WHERE a = 1 AND b > 2
ORDER BY c, d, f;
结合前两部分的分析,这个查询暗藏着两个核心需求的冲突:
- 一方面要通过a=1和b>2实现高效的数据筛选
- 另一方面要通过c,d,f的排序避免 filesort
这两个需求对索引字段的顺序安排提出了矛盾的要求 —— 筛选需要将查询条件字段前置,而排序需要将排序字段保持连续有序。
要化解这个矛盾,我们先从直觉出发设计两个候选联合索引:(a, b, c, d, f)和(a, c, d, f, b)。这两个方案都包含了所有关键字段,区别 仅在于是否用c,d,f将a和b隔开。要判断哪个方案更优,就必须深入理解 MySQL 的索引下推(ICP)特性,以及它如何与 B + 树的有序性原理结合发挥作用。
索引下推,在(a, b, c, d, f)中
这里先明确索引下推的核心逻辑:这是 MySQL 5.6 引入的优化技术,能将部分 WHERE 子句的过滤条件从服务层下推到存储引擎层执行。这样一来,存储引擎在扫描索引时就能提前过滤掉无效数据,减少返回给服务层的数据量,从而避免不必要的回表操作。
先看第一种设计(a, b, c, d, f)是否能满足需求。当 MySQL 使用这个索引时,确实能通过前缀a=1快速定位到目标数据区域,接着对b>2进行范围扫描。但问题恰恰出在范围扫描之后 —— 由于b是范围查询字段,根据 B + 树的有序性规则,b之后的c,d,f只能在每个b值的内部保持有序,跨b值时则完全打乱。
我们通过实际的数据顺序示例就能看清这个问题:
text(a=1, b=3, c=1, d=1, f=1) (a=1, b=3, c=1, d=1, f=2) (a=1, b=4, c=1, d=1, f=1) ← 跨b值后c,d,f重新开始排序 (a=1, b=4, c=1, d=1, f=2) (a=1, b=5, c=1, d=2, f=1)
这种局部有序性无法满足ORDER BY c, d, f的全局排序需求,MySQL 不得不将所有符合b>2的记录取出后执行 filesort,这正是我们要避免的性能损耗。
索引下推,在(a, c, d, f, b)中
再看(a, c, d, f, b)为何能破解这个难题。同样从 B + 树的有序性入手,这个索引将a作为前缀,紧接着是连续的c,d,f,最后才是b。当执行查询时,a=1的前缀定位依然高效,而c,d,f作为连续字段,在整个a=1的范围内保持了严格的全局有序性,这一点从数据顺序中清晰可见:
text(a=1, c=1, d=1, f=1, b=3) (a=1, c=1, d=1, f=1, b=4) (a=1, c=1, d=1, f=2, b=3) (a=1, c=1, d=1, f=2, b=4) (a=1, c=1, d=2, f=1, b=3)
这种全局有序性完美匹配了 ORDER BY c, d, f 的需求,MySQL 只需按索引的自然顺序扫描即可获得有序结果,彻底避免了 filesort。
而对于 b>2 的筛选条件,此时就需要索引下推发挥作用。虽然 b 位于索引末尾无法进行范围扫描,但存储引擎在扫描 a=1 范围内的 c,d,f 有序数据时,会同时检查每个叶子节点中的 b 值,直接过滤掉 b≤2 的记录。这个过滤过程在存储引擎层完成,意味着只有符合条件的记录才会被返回给服务层,大大减少了后续的回表操作数量。
这里需要澄清一个常见误解:索引下推并非用于 "联合" 多个索引,而是让单个联合索引具备了同时处理筛选与排序的能力。
(a, c, d, f, b)的设计正是利用了这一点 —— 通过字段顺序的巧妙安排,既保证了排序所需的全局有序性,又借助 ICP 特性实现了高效的条件筛选,最终达成了查询性能的最优解。
题外话:反常识的 ICP 应用 ——(b,a) 索引的 “救赎”
在此之外,我们还得提一下用 (b,a) 索引执行 a=1 AND b>2 。这个看似 “不匹配” 的索引,恰恰能帮我们快速抓牢 ICP 的核心原理。
当查询条件为 a=1 AND b>2 时,ICP(Index Condition Pushdown,索引下推)机制将发挥显著的优化作用:存储引擎利用 (b,a) 联合索引,优先扫描满足 b>2 的索引记录。然后,在扫描过程中,通过 ICP 将 a=1 的过滤条件下推至存储引擎层,同步检查索引项里的a值。
- 仅当
a=1时,才把主键(如 rowid)传给服务层,后续按需回表查询完整数据; - 对于
a≠1的记录,直接在存储引擎层丢弃,避免无谓的数据传输与服务层处理开销。
这一优化策略大幅减少了回表次数与服务层数据处理量,显著提升了查询性能。
总的来说,ICP 机制在 (b,a) 索引执行 a=1 AND b>2,就是依据他的宗旨:将部分 WHERE 子句的过滤条件从服务层下推到存储引擎层执行。
结语
燃尽了,从两点半写到十点还没写完,大概满打满算用了七八个小时写这篇文章。明线是按照解答这道 SQL 题目,暗线是按着串讲 MySQL 索引相关的内容,一篇串出来好多,写的时候也遇到自己理解不够透彻的内容,感觉自己讲不清楚,又去重新找资料问 AI 深入学习,也是我写 Blog 的初衷吧,用输出倒逼输入。